找到
685
篇与
阿贵
相关的结果
- 第 63 页
-
 Go语言字母异位词分组算法详细解析 Go语言字母异位词分组算法详细解析 下面我将从算法思路、代码结构、执行流程、复杂度分析和优化方向五个方面,详细解析这段Go语言实现的字母异位词分组算法。 leetcode.jpg图片 1. 算法思路 核心思想 字母异位词的特点是字母组成相同但排列顺序不同。基于此特点,我们可以: 将每个字符串排序,排序后的字符串作为异位词的统一标识 使用哈希表(map)存储:排序后字符串 → 原始字符串列表的映射 最后收集哈希表中的所有值作为结果 为什么这样设计? 排序:将不同顺序但相同字母组成的字符串统一化 哈希表:提供O(1)时间复杂度的查找和插入操作 分组收集:直接提取哈希表的值就是所需结果 2. 代码结构解析 import ( "sort" "strings" ) func groupAnagrams(strs []string) [][]string { // 1. 初始化哈希表 groups := make(map[string][]string) // 2. 遍历所有字符串 for _, str := range strs { // 2.1 字符串排序 s := strings.Split(str, "") sort.Strings(s) sortedStr := strings.Join(s, "") // 2.2 分组存储 groups[sortedStr] = append(groups[sortedStr], str) } // 3. 结果收集 result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }关键部分解析 字符串排序处理: s := strings.Split(str, "") // 将字符串拆分为字符切片 sort.Strings(s) // 对字符切片排序 sortedStr := strings.Join(s, "") // 重新组合为字符串 strings.Split(str, ""):将字符串拆分为单个字符组成的切片 sort.Strings(s):对字符切片进行字典序排序 strings.Join(s, ""):将排序后的字符切片重新组合为字符串 哈希表分组: groups[sortedStr] = append(groups[sortedStr], str) 使用排序后的字符串作为key 将原始字符串追加到对应的分组中 结果收集: result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } 预分配足够容量的切片(性能优化) 遍历哈希表的值并收集到结果切片中 3. 执行流程示例 以输入 ["eat","tea","tan","ate","nat","bat"] 为例: 原始字符串排序后哈希表变化"eat""aet"{"aet": ["eat"]}"tea""aet"{"aet": ["eat", "tea"]}"tan""ant"{"aet": ["eat", "tea"], "ant": ["tan"]}"ate""aet"{"aet": ["eat", "tea", "ate"], "ant": ["tan"]}"nat""ant"{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"]}"bat""abt"{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"], "abt": ["bat"]}最终结果:[["eat","tea","ate"],["tan","nat"],["bat"]] 4. 复杂度分析 时间复杂度 字符串排序:O(klogk),k是字符串长度 遍历所有字符串:O(n) 总时间复杂度:O(n*klogk) 空间复杂度 哈希表存储:O(n*k) 总空间复杂度:O(n*k) 其中: n:字符串数量 k:字符串的平均长度 5. 优化方向 1. 计数法优化(避免排序) func groupAnagrams(strs []string) [][]string { groups := make(map[[26]int][]string) for _, str := range strs { count := [26]int{} for _, c := range str { count[c-'a']++ } groups[count] = append(groups[count], str) } result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }优势: 时间复杂度降为O(n*k) 特别适合长字符串的情况 注意: Go中数组可以作为map key(切片不行) 需要处理Unicode时需扩展计数数组 2. 并行处理 对于超大字符串数组,可以: 将输入切片分成多个块 使用goroutine并行处理每个块 合并各个goroutine的结果 6. 关键点总结 排序是关键:通过排序将异位词统一化 哈希表高效分组:利用O(1)的查找和插入 Go语言特性: strings.Split/Join处理字符串 sort.Strings进行排序 map的灵活使用 性能考量: 预分配结果切片容量 考虑字符串长度选择排序法或计数法 这个实现充分展示了Go语言在处理字符串和哈希表方面的能力,代码清晰且效率较高。
Go语言字母异位词分组算法详细解析 Go语言字母异位词分组算法详细解析 下面我将从算法思路、代码结构、执行流程、复杂度分析和优化方向五个方面,详细解析这段Go语言实现的字母异位词分组算法。 leetcode.jpg图片 1. 算法思路 核心思想 字母异位词的特点是字母组成相同但排列顺序不同。基于此特点,我们可以: 将每个字符串排序,排序后的字符串作为异位词的统一标识 使用哈希表(map)存储:排序后字符串 → 原始字符串列表的映射 最后收集哈希表中的所有值作为结果 为什么这样设计? 排序:将不同顺序但相同字母组成的字符串统一化 哈希表:提供O(1)时间复杂度的查找和插入操作 分组收集:直接提取哈希表的值就是所需结果 2. 代码结构解析 import ( "sort" "strings" ) func groupAnagrams(strs []string) [][]string { // 1. 初始化哈希表 groups := make(map[string][]string) // 2. 遍历所有字符串 for _, str := range strs { // 2.1 字符串排序 s := strings.Split(str, "") sort.Strings(s) sortedStr := strings.Join(s, "") // 2.2 分组存储 groups[sortedStr] = append(groups[sortedStr], str) } // 3. 结果收集 result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }关键部分解析 字符串排序处理: s := strings.Split(str, "") // 将字符串拆分为字符切片 sort.Strings(s) // 对字符切片排序 sortedStr := strings.Join(s, "") // 重新组合为字符串 strings.Split(str, ""):将字符串拆分为单个字符组成的切片 sort.Strings(s):对字符切片进行字典序排序 strings.Join(s, ""):将排序后的字符切片重新组合为字符串 哈希表分组: groups[sortedStr] = append(groups[sortedStr], str) 使用排序后的字符串作为key 将原始字符串追加到对应的分组中 结果收集: result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } 预分配足够容量的切片(性能优化) 遍历哈希表的值并收集到结果切片中 3. 执行流程示例 以输入 ["eat","tea","tan","ate","nat","bat"] 为例: 原始字符串排序后哈希表变化"eat""aet"{"aet": ["eat"]}"tea""aet"{"aet": ["eat", "tea"]}"tan""ant"{"aet": ["eat", "tea"], "ant": ["tan"]}"ate""aet"{"aet": ["eat", "tea", "ate"], "ant": ["tan"]}"nat""ant"{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"]}"bat""abt"{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"], "abt": ["bat"]}最终结果:[["eat","tea","ate"],["tan","nat"],["bat"]] 4. 复杂度分析 时间复杂度 字符串排序:O(klogk),k是字符串长度 遍历所有字符串:O(n) 总时间复杂度:O(n*klogk) 空间复杂度 哈希表存储:O(n*k) 总空间复杂度:O(n*k) 其中: n:字符串数量 k:字符串的平均长度 5. 优化方向 1. 计数法优化(避免排序) func groupAnagrams(strs []string) [][]string { groups := make(map[[26]int][]string) for _, str := range strs { count := [26]int{} for _, c := range str { count[c-'a']++ } groups[count] = append(groups[count], str) } result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }优势: 时间复杂度降为O(n*k) 特别适合长字符串的情况 注意: Go中数组可以作为map key(切片不行) 需要处理Unicode时需扩展计数数组 2. 并行处理 对于超大字符串数组,可以: 将输入切片分成多个块 使用goroutine并行处理每个块 合并各个goroutine的结果 6. 关键点总结 排序是关键:通过排序将异位词统一化 哈希表高效分组:利用O(1)的查找和插入 Go语言特性: strings.Split/Join处理字符串 sort.Strings进行排序 map的灵活使用 性能考量: 预分配结果切片容量 考虑字符串长度选择排序法或计数法 这个实现充分展示了Go语言在处理字符串和哈希表方面的能力,代码清晰且效率较高。
-
字母异位词分组:Go/Java/Python最优解法详解 字母异位词分组:Go/Java/Python最优解法详解 问题描述 字母异位词(Anagram)是指由相同字母重新排列组合形成的不同单词。本题要求: 给定一个字符串数组 strs,将其中所有字母异位词组合在一起,可以按任意顺序返回结果列表。 leetcode.jpg图片 示例:输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"] 输出: [["bat"],["nat","tan"],["ate","eat","tea"]]解题思路 核心思路 字母异位词的特点是字母组成相同但顺序不同。我们可以利用这个特点: 将每个字符串排序,排序后的字符串作为异位词的统一标识 使用哈希表存储:排序后字符串 → 原始字符串列表的映射 最后将哈希表中的所有值收集起来就是结果 复杂度分析 时间复杂度:O(n*klogk),n是字符串数量,k是字符串最大长度(排序每个字符串的耗时) 空间复杂度:O(nk),需要存储所有字符串 各语言最优实现 Go实现 import ( "sort" "strings" ) func groupAnagrams(strs []string) [][]string { groups := make(map[string][]string) for _, str := range strs { // 将字符串转为字符数组并排序 s := strings.Split(str, "") sort.Strings(s) sortedStr := strings.Join(s, "") // 将原始字符串加入对应分组 groups[sortedStr] = append(groups[sortedStr], str) } // 收集结果 result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }特点: 使用strings.Split和sort.Strings进行字符串排序 make(map[string][]string)创建哈希表 最后需要将map转为slice Java实现 import java.util.*; class Solution { public List<List<String>> groupAnagrams(String[] strs) { Map<String, List<String>> map = new HashMap<>(); for (String str : strs) { // 将字符串转为字符数组并排序 char[] chars = str.toCharArray(); Arrays.sort(chars); String sorted = new String(chars); // 如果不存在该key,则新建一个列表 if (!map.containsKey(sorted)) { map.put(sorted, new ArrayList<>()); } map.get(sorted).add(str); } return new ArrayList<>(map.values()); } }特点: 使用Arrays.sort()对字符数组排序 需要处理key不存在的情况 new ArrayList<>(map.values())直接转换结果 Python3实现 from collections import defaultdict def groupAnagrams(strs): groups = defaultdict(list) for s in strs: # 排序字符串作为key key = "".join(sorted(s)) groups[key].append(s) return list(groups.values())特点: 使用defaultdict简化代码 sorted(s)直接返回排序后的字符列表 代码最为简洁 边界情况测试 测试用例说明预期结果[""]空字符串[[""]]["a"]单个字符[["a"]]["eat","tea","tan","ate","nat","bat"]常规情况[["bat"],["nat","tan"],["ate","eat","tea"]]["abc","cba","bac","def","fed"]多个分组[["def","fed"],["abc","cba","bac"]]算法优化思路 计数法优化(避免排序) 我们可以统计每个字符串中各个字母的出现次数,用计数作为key: def groupAnagrams(strs): groups = defaultdict(list) for s in strs: count = [0] * 26 for c in s: count[ord(c) - ord('a')] += 1 groups[tuple(count)].append(s) return list(groups.values())复杂度分析: 时间复杂度:O(n*k),n是字符串数量,k是字符串最大长度 空间复杂度:O(nk) 这种方法在字符串较长时效率更高。 实际应用场景 单词游戏:如 Scrabble 等字母排列游戏 文本分析:查找相似单词 密码学:分析字母频率模式 数据清洗:识别和合并相似条目 总结 字母异位词分组问题的核心在于: 找到合适的分组标识(排序后的字符串或字母计数) 使用哈希表高效分组 处理各种边界情况 三种语言的实现展示了不同语言的特性: Go:显式类型转换较多,性能优秀 Java:类型系统严格,代码稍显冗长 Python:利用高级数据结构,代码最简洁 建议读者: 先理解排序法的思路 尝试实现计数法优化 比较不同语言的实现差异 扩展思考 如果字符串包含Unicode字符,如何修改算法? 如何优化内存使用,特别是处理大量长字符串时? 如何并行化处理这个分组问题? 希望这篇文章能帮助你彻底掌握字母异位词分组问题!如有任何疑问,欢迎在评论区讨论。
-
一篇文章彻底掌握「两数之和」:Go语言写法最优解法详解 问题描述 「两数之和」是LeetCode上最经典的算法题之一,题目要求: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 target 的那两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 leetcode.jpg图片 示例: 输入:nums = [2, 7, 11, 15], target = 9 输出:[0, 1](因为 nums[0] + nums[1] = 2 + 7 = 9) 2. 算法思路 暴力法(Brute Force) 最直观的方法是双重循环遍历所有可能的组合,时间复杂度 O(n²),但效率较低。 哈希表优化法(最优解) 利用 哈希表(Hash Map) 存储 值 → 索引 的映射,只需遍历一次数组: 遍历数组,计算 target - nums[i] 是否在哈希表中。 如果在,说明找到了解,直接返回两个索引。 如果不在,把当前 nums[i] 存入哈希表,继续遍历。 时间复杂度:O(n)(只需遍历一次) 空间复杂度:O(n)(需要存储哈希表) 3. 代码解析 修正后的代码 package main import "fmt" func twoSum(nums []int, target int) []int { m := make(map[int]int) // 哈希表:存储 值 → 索引 的映射 for i, v := range nums { if k, ok := m[target-v]; ok { // 检查 target - v 是否在哈希表中 return []int{k, i} // 如果存在,返回两个索引 } m[v] = i // 否则,存入当前值及其索引 } return nil // 没找到解,返回 nil } func main() { result := twoSum([]int{2, 7, 11, 15}, 9) fmt.Println(result) // 输出 [0, 1] }逐行解析 m := make(map[int]int) 创建哈希表 m,用于存储 值 → 索引 的映射。 for i, v := range nums 遍历数组 nums,i 是索引,v 是当前值。 if k, ok := m[target-v]; ok 检查 target - v 是否在哈希表中: 如果存在 ok = true,说明之前已经存储了一个数 nums[k],使得 nums[k] + v = target。 直接返回 [k, i]。 m[v] = i 如果没找到匹配,就把当前 v 和它的索引 i 存入哈希表,供后续查找。 return nil 如果遍历完数组仍然没找到解,返回 nil(Go 里表示空切片)。 main() 函数 调用 twoSum 并打印结果。 4. 执行流程(以 nums = [2, 7, 11, 15], target = 9 为例) 步骤ivtarget - v哈希表 m是否找到?操作1029 - 2 = 7{}否m[2] = 02179 - 7 = 2{2:0}是(m[2] = 0)返回 [0, 1]最终输出:[0, 1] 5. 复杂度分析 方法时间复杂度空间复杂度暴力法(双重循环)O(n²)O(1)哈希表优化法O(n)O(n) 时间复杂度 O(n):只需遍历一次数组,哈希表查找是 O(1)。 空间复杂度 O(n):最坏情况下需要存储所有元素。 6. 边界情况 无解情况 如果 nums = [1, 2, 3], target = 7,返回 nil。 重复元素 nums = [3, 3], target = 6 → 返回 [0, 1](哈希表不会覆盖,因为找到解时直接返回)。 负数 & 零 nums = [-1, 0, 1], target = 0 → 返回 [0, 2]。 空数组 nums = [], target = 1 → 返回 nil。 7. 总结 最优解法:哈希表(O(n) 时间,O(n) 空间)。 核心思路:用哈希表存储遍历过的值,避免重复计算。 Go 实现要点: map[int]int 存储 值 → 索引。 if k, ok := m[target-v]; ok 判断是否存在解。 main() 不能有返回值,应该打印结果。 这样,这段代码就能高效地解决 Two Sum 问题! 🚀
-
两数之和(Two Sum)问题详解:一篇文章彻底掌握「两数之和」Go/Java/Python 最优解法详解 一篇文章彻底掌握「两数之和」:Go/Java/Python 最优解法详解 问题描述 「两数之和」是LeetCode上最经典的算法题之一,题目要求: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 target 的那两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 leetcode.jpg图片 示例: 输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9,返回 [0, 1]解法思路分析 1. 暴力解法(不推荐) 最直观的方法是双重循环遍历所有可能的组合: def twoSum(nums, target): for i in range(len(nums)): for j in range(i+1, len(nums)): if nums[i] + nums[j] == target: return [i, j] 时间复杂度:O(n²) 空间复杂度:O(1) 2. 哈希表优化解法(最优解) 利用哈希表存储已经遍历过的数字及其索引,可以将时间复杂度降为O(n): 各语言最优实现 Go 实现 func twoSum(nums []int, target int) []int { m := make(map[int]int) for i, v := range nums { if k, ok := m[target-v]; ok { return []int{k, i} } m[v] = i } return nil }特点: 使用map[int]int存储值到索引的映射 if k, ok := m[target-v]; ok 是Go特有的map访问方式 清晰简洁,性能优秀 Java 实现 class Solution { public int[] twoSum(int[] nums, int target) { Map<Integer, Integer> map = new HashMap<>(); for (int i = 0; i < nums.length; i++) { int complement = target - nums[i]; if (map.containsKey(complement)) { return new int[] {map.get(complement), i}; } map.put(nums[i], i); } throw new IllegalArgumentException("No two sum solution"); } }特点: 使用HashMap存储数据 需要处理无解情况(抛出异常) 类型系统更严格 Python3 实现 def twoSum(nums, target): hashmap = {} for i, num in enumerate(nums): complement = target - num if complement in hashmap: return [hashmap[complement], i] hashmap[num] = i return None特点: 使用字典存储数据 enumerate获取索引和值 代码最为简洁 算法分析 时间复杂度 三种实现的时间复杂度都是O(n),因为: 只需要遍历数组一次 哈希表的查找操作是O(1)时间复杂度 空间复杂度 空间复杂度都是O(n),因为: 最坏情况下需要存储所有元素到哈希表 边界情况测试 测试用例说明预期结果[2,7,11,15], 9常规情况[0,1][3,2,4], 6非顺序解[1,2][3,3], 6相同元素[0,1][1,2,3], 7无解情况nil/null/None[-1,0,1], 0含负数[0,2]实际应用场景 支付系统:查找两笔交易金额之和等于特定值 游戏开发:查找两个物品的组合效果 数据分析:找出满足特定条件的两个数据点 总结 「两数之和」问题虽然简单,但包含了算法设计的核心思想: 从暴力解法入手理解问题 通过空间换时间优化性能 考虑各种边界情况 掌握不同语言的实现特点 三种语言的实现虽然语法不同,但核心算法思想完全一致。建议读者: 先理解算法思路 然后学习自己主要使用语言的实现 最后尝试用其他语言实现以加深理解 扩展思考 如果数组已排序,是否有更优解法?(可以使用双指针法,空间复杂度O(1)) 如果要求返回所有可能的解而不仅是一个,如何修改代码? 如果数组非常大,如何优化内存使用? 希望这篇文章能帮助你彻底掌握「两数之和」问题!如果有任何疑问,欢迎在评论区留言讨论。
-
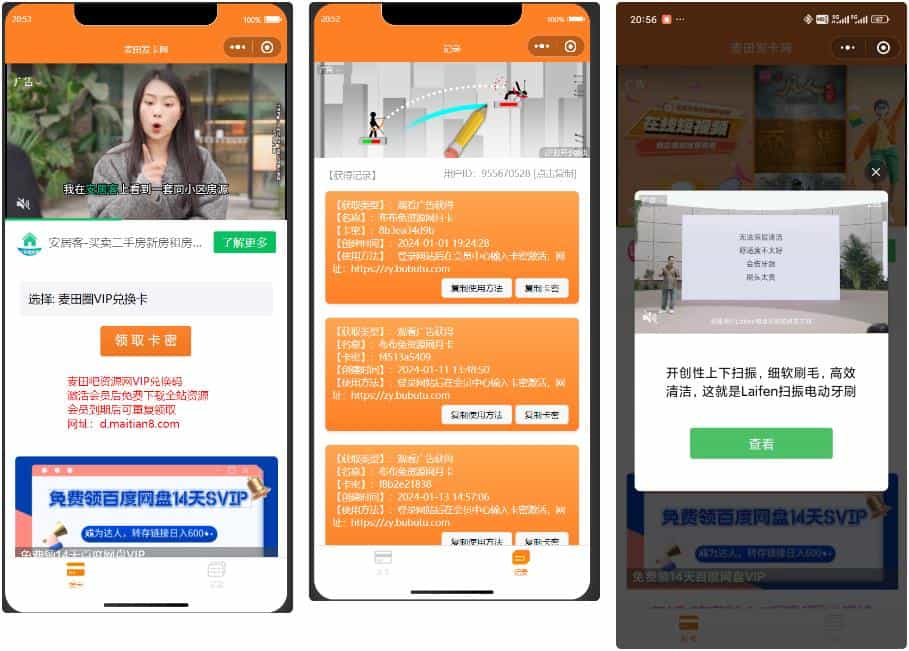
新版微信发卡小程序源码二开优化版:支持流量主与多种领取模式 新版微信发卡小程序源码二开优化版:支持流量主与多种领取模式 项目介绍 今天给大家分享一款经过二次开发的微信发卡小程序源码,该系统基于PHP开发,支持卡密发放、流量主广告接入以及多种领取模式。我在原版基础上进行了多项功能优化和BUG修复,测试搭建表现良好,现分享给需要的开发者。 fk1.jpg图片 fk2.jpg图片 fk3.jpg图片 功能特点 核心功能 多种卡密领取模式: 直接领取 观看广告领取 广告+分享领取 付费购买领取 完善的卡密管理: 支持添加分类及分类介绍 支持批量导入卡密 提供卡密使用说明 二开优化内容 修复分类介绍报错 - 解决了原版中分类介绍功能存在的BUG 前端UI优化 - 改进了用户界面,提升用户体验 新增插屏广告 - 增加流量主收益渠道 禁止PC端使用 - 因为PC端小程序无法展示广告,故屏蔽了PC端访问 技术架构 后端:PHP 5.6+(推荐7.0+) 前端:微信小程序原生开发 数据库:MySQL 安全要求:HTTPS强制访问 安装教程 后端部署 环境准备: 准备一个已解析的域名(二级域名也可) 确保服务器支持PHP 5.6及以上版本 部署步骤: # 1. 上传后端源码至宝塔面板 # 2. 在宝塔解压源码 # 3. 访问 你的域名/install 进行安装 # 4. 后台地址:你的域名/admin 重要配置: 在后台设置你的小程序AppID和秘钥 开启HTTPS强制访问(宝塔面板可免费获取SSL证书) 前端部署 导入项目: 将前端文件导入微信开发者工具 修改配置: // 修改app.js中的网站地址 const baseUrl = "https://yourdomain.com"; 微信平台配置: 在微信公众平台→开发→开发管理→开发设置→服务器域名中,添加你的HTTPS域名 注意事项 PHP加密:源码为开源版本,如需加密可使用免费PHP加密平台:php.javait.cn 广告接入:确保小程序已开通流量主功能,并在代码中正确配置广告位ID 性能优化:建议使用PHP7+版本以获得更好性能 安全建议:定期备份数据库,避免卡密数据丢失 下载地址 隐藏内容,请前往内页查看详情 总结 这套经过二次开发的发卡小程序源码功能完善,特别适合需要卡密发放的场景,如: 软件激活码分发 会员卡号发放 课程兑换码发放 游戏礼包码发放 通过多种领取模式的设计,可以有效平衡用户体验和商业收益。流量主广告的接入也为运营者提供了可持续的盈利方式。 如果你在部署过程中遇到任何问题,欢迎在评论区留言交流!