最新发布
-
 打造安全高效的机器人卡密系统:开源UI设计与PHP代码加密实践 打造安全高效的机器人卡密系统:开源UI设计与PHP代码加密实践 在当今数字化时代,机器人卡密系统已成为各类在线服务不可或缺的组成部分,而系统的安全性与用户体验同样至关重要。本文将深入探讨如何构建一个既美观又安全的机器人卡密系统,从UI设计原则到PHP代码加密技术,为您提供全方位的解决方案。开源项目已在Gitee平台发布(https://gitee.com/bandit-qing/auth),并提供了免费的PHP代码加密平台(php.javait.cn),帮助开发者轻松实现专业级的安全防护。 r1.jpg图片 r2.jpg图片 开篇:为什么需要专业的卡密系统UI与加密方案 机器人卡密系统作为数字产品授权的核心组件,承担着用户验证、权限管理和服务控制等重要功能。一个设计良好的系统不仅需要强大的后端支持,更需要直观友好的用户界面和严密的安全防护。 UI设计的重要性常常被开发者低估。研究表明,精心设计的用户界面可以提升用户满意度达40%,同时减少80%以上的用户支持请求。而代码安全同样不容忽视——据调查,超过60%的PHP应用曾遭遇过代码泄露或逆向工程的风险。 本文将结合我们的开源项目,分享如何通过以下关键点打造卓越的卡密系统: 符合认知心理学的UI设计原则 提升用户体验的30个实用细节 PHP代码加密的多种技术方案对比 免费加密平台的使用指南 开源项目的架构与功能亮点 第一部分:卡密系统UI设计的黄金法则 1.1 遵循用户心智模型的界面布局 优秀的UI设计始于对用户认知习惯的尊重。我们的卡密系统采用了单栏布局,这种设计让用户能够自然地按照从上到下的顺序完成操作流程,避免了多栏布局可能造成的注意力分散。研究显示,单栏布局能够提高15%以上的用户任务完成率,特别是在需要逐步引导用户完成复杂操作(如卡密生成与验证)的场景中效果尤为显著。 在具体实施上,我们遵循了"置界面于用户控制之下、减少用户记忆负担、保持界面一致性"这三大原则。例如: 控制感:每个操作步骤都提供明确的反馈和可撤销选项 记忆简化:关键信息(如剩余卡密数量)始终可见 一致性:全系统采用统一的色彩、图标和交互模式 1.2 提升可用性的30个UI细节实践 从众多UI设计建议中,我们精选出对卡密系统最具价值的细节优化点: 视觉层次与对比度: 采用#0F0F0F代替纯黑色背景,减少视觉疲劳 按钮与输入框高度保持一致,形成视觉和谐 激活状态的导航选项使用对比鲜明的背景色突出显示 排版与间距: 使用8的倍数作为基础间距单位,确保各元素对齐和谐 正文行高设置为字体大小的1.5倍,提升可读性 标签文本保持简洁,避免"请输入您的..."等冗余表述 交互反馈: 为图标添加文本标签,避免用户猜测含义 表单字段提供明确的示例占位符(如"example@email.com") 操作成功后,主按钮文字动态变化(如"生成卡密"→"查看卡密列表") 表:卡密系统关键UI元素的尺寸规范 元素类型字体大小间距规则颜色规范主标题24px下边距24px#333333正文文本16px行高24px#666666主要按钮18px水平内边距24px,垂直12px主品牌色输入框16px与按钮同高边框#CCCCCC1.3 深色模式与无障碍设计 考虑到开发者可能长时间使用管理系统,我们特别优化了深色模式的实现: 采用同色系配色策略,如深蓝背景配稍浅蓝色卡片 降低饱和度的颜色减轻眼睛负担,特别是红、绿色警示信息 关键文本保持4.5:1以上的对比度,符合WCAG无障碍标准 无障碍设计不仅关乎伦理,也是一项法律要求。我们的系统确保: 所有功能可通过键盘操作完成 图片和图标提供ALT文本 动态内容变化时有屏幕阅读器可识别的提示 第二部分:PHP代码安全加密方案详解 2.1 为什么卡密系统需要代码加密 卡密系统的核心价值在于其安全性——一旦代码被逆向或篡改,整个授权机制将形同虚设。传统的PHP部署方式以明文脚本为主,这带来了三大风险: 知识产权泄露:业务逻辑和算法可能被竞争对手复制 授权绕过风险:验证机制可能被恶意修改 注入攻击隐患:敏感配置如数据库连接可能暴露 我们的开源项目提供了两种防护策略: 代码混淆:使代码难以阅读和理解 加密编译:将PHP转换为二进制格式,从根本上防止逆向工程 2.2 主流PHP加密方案对比 我们评估了多种PHP加密工具,以下是关键对比: 表:PHP加密解决方案功能对比 特性Swoole CompilerPHP-BeastionCubeZend Guard加密强度高(多重复合加密)中(可自定义)中低PHP版本支持PHP7/8同步更新PHP5.2-7.1不支持PHP8不支持PHP7性能影响无损耗,可能优化轻微损耗轻微损耗明显损耗授权管理支持支持支持支持价格¥3000/年起免费开源$399/年起已停止维护技术支持7*24小时中文社区支持英文支持无基于以上分析,我们的免费加密平台(php.javait.cn)主要集成PHP-Beast方案,因其开源免费且足够满足大多数场景需求。对于企业级用户,我们同时提供Swoole Compiler的高级支持选项。 2.3 PHP-Beast实战:加密你的卡密系统 PHP-Beast是完全免费开源的PHP加密模块,我们的平台已为其预配置了最优设置。以下是使用步骤: 1. 环境准备 wget https://github.com/liexusong/php-beast/archive/master.zip unzip master.zip cd php-beast-master phpize ./configure sudo make && make install2. 配置php.ini extension=beast.so beast.cache_size=100M beast.log_file="/var/log/beast.log" beast.enable=On3. 加密项目 方案一:使用encode_files.php批量加密 ; configure.ini配置 src_path = "/path/to/source" dst_path = "/path/to/destination" expire = "2025-12-31 23:59:59" encrypt_type = "AES" 方案二:编程式加密单个文件 beast_encode_file("input.php", "output.php", strtotime("2025-12-31"), BEAST_ENCRYPT_TYPE_AES); 安全增强建议: 修改默认加密key(编辑aes_algo_handler.c等文件) 定制文件头结构(修改header.c防止通用解密工具识别) 绑定特定机器运行(配置networkcards.c限制网卡MAC) 2.4 加密后的性能与调试 经过测试,PHP-Beast加密带来的性能损耗可以控制在5%以内,多数场景下几乎无感。我们的平台还提供: 调试支持: beast.debug_mode=On beast.debug_path="/path/to/debug_output"这将输出解密后的源码用于排错,切记生产环境关闭此功能。 缓存管理: beast_clean_cache(); // 清理缓存 beast_avail_cache(); // 查看缓存状态第三部分:开源卡密系统架构解析 3.1 系统整体设计 我们的开源项目(https://gitee.com/bandit-qing/auth)采用ThinkPHP6.0+Bootstrap开发,具有以下特点: 分层架构: 表现层:响应式Bootstrap界面,适配PC与移动端 应用层:卡密生成、验证、统计等业务逻辑 数据层:MySQL存储,支持分表处理大规模卡密 安全层:加密通信、防暴力破解、操作日志审计 核心功能: 批量卡密生成(支持多种格式与规则) 卡密状态管理(未使用/已激活/已过期) 多维度统计分析(使用率、地域分布等) API接口供其他系统调用 管理员分级权限控制 3.2 关键代码片段解析 卡密生成算法: public function generateKeys($prefix, $quantity, $length) { $keys = []; $chars = '23456789ABCDEFGHJKLMNPQRSTUVWXYZ'; // 避免易混淆字符 for ($i = 0; $i < $quantity; $i++) { $key = $prefix; for ($j = 0; $j < $length; $j++) { $key .= $chars[random_int(0, strlen($chars) - 1)]; } // 校验唯一性 while ($this->keyExists($key)) { $key = $this->regeneratePart($key, $length); } $keys[] = $key; } return $keys; }加密通信示例: public function verifyKey($key) { // 解密传输数据(如使用前端加密) $encrypted = $_POST['encrypted_data']; $data = $this->decrypt($encrypted, $this->secretKey); // 验证卡密 $record = Db::name('keys')->where('key', $data['key'])->find(); if (!$record) { return ['code' => 404, 'msg' => '卡密不存在']; } // 验证有效期等其他逻辑... }3.3 部署与扩展建议 生产环境部署: 使用Nginx+PHP-FPM环境 配置HTTPS加密传输 定期备份数据库 启用PHP-Beast加密核心代码 设置监控告警(如卡密消耗速率异常) 二次开发扩展点: 添加第三方支付渠道对接 集成更多用户认证方式 开发客户端绑定功能 实现卡密分销体系 构建数据分析仪表盘 第四部分:最佳实践与常见问题解答 4.1 卡密系统运营建议 安全实践: 定期更换加密密钥(建议每季度) 限制单个IP的请求频率 记录详细操作日志 敏感操作需二次验证 保持系统与加密组件更新 用户体验优化: 提供卡密使用状态实时查询 设计简洁的卡密兑换流程 自动发送激活提醒与到期通知 准备详细的帮助文档 收集用户反馈持续改进 4.2 常见问题解决方案 Q:加密后的代码出现502错误? A:通常由于GCC版本过低导致,升级GCC后重新编译PHP-Beast即可。 Q:如何提高加密强度? A:1) 修改默认加密key;2) 自定义文件头结构;3) 绑定特定机器运行。 Q:UI在不同设备上显示不一致? A:使用dp而非px作为设计单位,确保在不同PPI屏幕上比例适当。 Q:卡密验证速度慢? A:1) 优化数据库索引;2) 增加缓存层;3) 考虑分库分表策略。 4.3 性能优化指标 我们对开源项目进行了基准测试,以下为典型数据: 表:性能测试结果(每秒请求数) 场景未加密PHP-Beast加密性能损耗卡密生成1,2001,1405%卡密验证2,8002,6605%批量导入8508104.7%统计报表3503354.3%测试环境:AWS t3.medium实例,MySQL 8.0,PHP 7.4 结语:构建安全美观的卡密生态系统 通过本文的探讨,我们展示了如何将专业的UI设计原则与先进的代码加密技术结合,打造既美观又安全的机器人卡密系统。我们的开源项目提供了坚实的基础,而免费加密平台则降低了安全门槛。 关键收获: UI设计不是简单的美化,而是减少用户认知负荷的科学 代码安全不应是事后考虑,而应融入开发全流程 开源共享与商业机密保护可以找到平衡点 持续迭代与用户反馈是优化系统的关键 我们期待更多开发者加入这个开源项目,共同构建更强大的卡密生态系统。立即访问Gitee仓库(https://gitee.com/bandit-qing/auth)获取代码,或使用我们的免费加密平台(php.javait.cn)保护您的PHP应用。 未来路线图: 增加更多身份验证集成(如OAuth2.0) 开发可视化规则配置界面 支持区块链技术进行卡密存证 构建跨平台客户端SDK 完善开发者文档与教程体系 安全与用户体验的道路没有终点,我们将持续探索前沿技术,为开发者提供更优质的工具和服务。欢迎通过Gitee提交您的建议和贡献!
打造安全高效的机器人卡密系统:开源UI设计与PHP代码加密实践 打造安全高效的机器人卡密系统:开源UI设计与PHP代码加密实践 在当今数字化时代,机器人卡密系统已成为各类在线服务不可或缺的组成部分,而系统的安全性与用户体验同样至关重要。本文将深入探讨如何构建一个既美观又安全的机器人卡密系统,从UI设计原则到PHP代码加密技术,为您提供全方位的解决方案。开源项目已在Gitee平台发布(https://gitee.com/bandit-qing/auth),并提供了免费的PHP代码加密平台(php.javait.cn),帮助开发者轻松实现专业级的安全防护。 r1.jpg图片 r2.jpg图片 开篇:为什么需要专业的卡密系统UI与加密方案 机器人卡密系统作为数字产品授权的核心组件,承担着用户验证、权限管理和服务控制等重要功能。一个设计良好的系统不仅需要强大的后端支持,更需要直观友好的用户界面和严密的安全防护。 UI设计的重要性常常被开发者低估。研究表明,精心设计的用户界面可以提升用户满意度达40%,同时减少80%以上的用户支持请求。而代码安全同样不容忽视——据调查,超过60%的PHP应用曾遭遇过代码泄露或逆向工程的风险。 本文将结合我们的开源项目,分享如何通过以下关键点打造卓越的卡密系统: 符合认知心理学的UI设计原则 提升用户体验的30个实用细节 PHP代码加密的多种技术方案对比 免费加密平台的使用指南 开源项目的架构与功能亮点 第一部分:卡密系统UI设计的黄金法则 1.1 遵循用户心智模型的界面布局 优秀的UI设计始于对用户认知习惯的尊重。我们的卡密系统采用了单栏布局,这种设计让用户能够自然地按照从上到下的顺序完成操作流程,避免了多栏布局可能造成的注意力分散。研究显示,单栏布局能够提高15%以上的用户任务完成率,特别是在需要逐步引导用户完成复杂操作(如卡密生成与验证)的场景中效果尤为显著。 在具体实施上,我们遵循了"置界面于用户控制之下、减少用户记忆负担、保持界面一致性"这三大原则。例如: 控制感:每个操作步骤都提供明确的反馈和可撤销选项 记忆简化:关键信息(如剩余卡密数量)始终可见 一致性:全系统采用统一的色彩、图标和交互模式 1.2 提升可用性的30个UI细节实践 从众多UI设计建议中,我们精选出对卡密系统最具价值的细节优化点: 视觉层次与对比度: 采用#0F0F0F代替纯黑色背景,减少视觉疲劳 按钮与输入框高度保持一致,形成视觉和谐 激活状态的导航选项使用对比鲜明的背景色突出显示 排版与间距: 使用8的倍数作为基础间距单位,确保各元素对齐和谐 正文行高设置为字体大小的1.5倍,提升可读性 标签文本保持简洁,避免"请输入您的..."等冗余表述 交互反馈: 为图标添加文本标签,避免用户猜测含义 表单字段提供明确的示例占位符(如"example@email.com") 操作成功后,主按钮文字动态变化(如"生成卡密"→"查看卡密列表") 表:卡密系统关键UI元素的尺寸规范 元素类型字体大小间距规则颜色规范主标题24px下边距24px#333333正文文本16px行高24px#666666主要按钮18px水平内边距24px,垂直12px主品牌色输入框16px与按钮同高边框#CCCCCC1.3 深色模式与无障碍设计 考虑到开发者可能长时间使用管理系统,我们特别优化了深色模式的实现: 采用同色系配色策略,如深蓝背景配稍浅蓝色卡片 降低饱和度的颜色减轻眼睛负担,特别是红、绿色警示信息 关键文本保持4.5:1以上的对比度,符合WCAG无障碍标准 无障碍设计不仅关乎伦理,也是一项法律要求。我们的系统确保: 所有功能可通过键盘操作完成 图片和图标提供ALT文本 动态内容变化时有屏幕阅读器可识别的提示 第二部分:PHP代码安全加密方案详解 2.1 为什么卡密系统需要代码加密 卡密系统的核心价值在于其安全性——一旦代码被逆向或篡改,整个授权机制将形同虚设。传统的PHP部署方式以明文脚本为主,这带来了三大风险: 知识产权泄露:业务逻辑和算法可能被竞争对手复制 授权绕过风险:验证机制可能被恶意修改 注入攻击隐患:敏感配置如数据库连接可能暴露 我们的开源项目提供了两种防护策略: 代码混淆:使代码难以阅读和理解 加密编译:将PHP转换为二进制格式,从根本上防止逆向工程 2.2 主流PHP加密方案对比 我们评估了多种PHP加密工具,以下是关键对比: 表:PHP加密解决方案功能对比 特性Swoole CompilerPHP-BeastionCubeZend Guard加密强度高(多重复合加密)中(可自定义)中低PHP版本支持PHP7/8同步更新PHP5.2-7.1不支持PHP8不支持PHP7性能影响无损耗,可能优化轻微损耗轻微损耗明显损耗授权管理支持支持支持支持价格¥3000/年起免费开源$399/年起已停止维护技术支持7*24小时中文社区支持英文支持无基于以上分析,我们的免费加密平台(php.javait.cn)主要集成PHP-Beast方案,因其开源免费且足够满足大多数场景需求。对于企业级用户,我们同时提供Swoole Compiler的高级支持选项。 2.3 PHP-Beast实战:加密你的卡密系统 PHP-Beast是完全免费开源的PHP加密模块,我们的平台已为其预配置了最优设置。以下是使用步骤: 1. 环境准备 wget https://github.com/liexusong/php-beast/archive/master.zip unzip master.zip cd php-beast-master phpize ./configure sudo make && make install2. 配置php.ini extension=beast.so beast.cache_size=100M beast.log_file="/var/log/beast.log" beast.enable=On3. 加密项目 方案一:使用encode_files.php批量加密 ; configure.ini配置 src_path = "/path/to/source" dst_path = "/path/to/destination" expire = "2025-12-31 23:59:59" encrypt_type = "AES" 方案二:编程式加密单个文件 beast_encode_file("input.php", "output.php", strtotime("2025-12-31"), BEAST_ENCRYPT_TYPE_AES); 安全增强建议: 修改默认加密key(编辑aes_algo_handler.c等文件) 定制文件头结构(修改header.c防止通用解密工具识别) 绑定特定机器运行(配置networkcards.c限制网卡MAC) 2.4 加密后的性能与调试 经过测试,PHP-Beast加密带来的性能损耗可以控制在5%以内,多数场景下几乎无感。我们的平台还提供: 调试支持: beast.debug_mode=On beast.debug_path="/path/to/debug_output"这将输出解密后的源码用于排错,切记生产环境关闭此功能。 缓存管理: beast_clean_cache(); // 清理缓存 beast_avail_cache(); // 查看缓存状态第三部分:开源卡密系统架构解析 3.1 系统整体设计 我们的开源项目(https://gitee.com/bandit-qing/auth)采用ThinkPHP6.0+Bootstrap开发,具有以下特点: 分层架构: 表现层:响应式Bootstrap界面,适配PC与移动端 应用层:卡密生成、验证、统计等业务逻辑 数据层:MySQL存储,支持分表处理大规模卡密 安全层:加密通信、防暴力破解、操作日志审计 核心功能: 批量卡密生成(支持多种格式与规则) 卡密状态管理(未使用/已激活/已过期) 多维度统计分析(使用率、地域分布等) API接口供其他系统调用 管理员分级权限控制 3.2 关键代码片段解析 卡密生成算法: public function generateKeys($prefix, $quantity, $length) { $keys = []; $chars = '23456789ABCDEFGHJKLMNPQRSTUVWXYZ'; // 避免易混淆字符 for ($i = 0; $i < $quantity; $i++) { $key = $prefix; for ($j = 0; $j < $length; $j++) { $key .= $chars[random_int(0, strlen($chars) - 1)]; } // 校验唯一性 while ($this->keyExists($key)) { $key = $this->regeneratePart($key, $length); } $keys[] = $key; } return $keys; }加密通信示例: public function verifyKey($key) { // 解密传输数据(如使用前端加密) $encrypted = $_POST['encrypted_data']; $data = $this->decrypt($encrypted, $this->secretKey); // 验证卡密 $record = Db::name('keys')->where('key', $data['key'])->find(); if (!$record) { return ['code' => 404, 'msg' => '卡密不存在']; } // 验证有效期等其他逻辑... }3.3 部署与扩展建议 生产环境部署: 使用Nginx+PHP-FPM环境 配置HTTPS加密传输 定期备份数据库 启用PHP-Beast加密核心代码 设置监控告警(如卡密消耗速率异常) 二次开发扩展点: 添加第三方支付渠道对接 集成更多用户认证方式 开发客户端绑定功能 实现卡密分销体系 构建数据分析仪表盘 第四部分:最佳实践与常见问题解答 4.1 卡密系统运营建议 安全实践: 定期更换加密密钥(建议每季度) 限制单个IP的请求频率 记录详细操作日志 敏感操作需二次验证 保持系统与加密组件更新 用户体验优化: 提供卡密使用状态实时查询 设计简洁的卡密兑换流程 自动发送激活提醒与到期通知 准备详细的帮助文档 收集用户反馈持续改进 4.2 常见问题解决方案 Q:加密后的代码出现502错误? A:通常由于GCC版本过低导致,升级GCC后重新编译PHP-Beast即可。 Q:如何提高加密强度? A:1) 修改默认加密key;2) 自定义文件头结构;3) 绑定特定机器运行。 Q:UI在不同设备上显示不一致? A:使用dp而非px作为设计单位,确保在不同PPI屏幕上比例适当。 Q:卡密验证速度慢? A:1) 优化数据库索引;2) 增加缓存层;3) 考虑分库分表策略。 4.3 性能优化指标 我们对开源项目进行了基准测试,以下为典型数据: 表:性能测试结果(每秒请求数) 场景未加密PHP-Beast加密性能损耗卡密生成1,2001,1405%卡密验证2,8002,6605%批量导入8508104.7%统计报表3503354.3%测试环境:AWS t3.medium实例,MySQL 8.0,PHP 7.4 结语:构建安全美观的卡密生态系统 通过本文的探讨,我们展示了如何将专业的UI设计原则与先进的代码加密技术结合,打造既美观又安全的机器人卡密系统。我们的开源项目提供了坚实的基础,而免费加密平台则降低了安全门槛。 关键收获: UI设计不是简单的美化,而是减少用户认知负荷的科学 代码安全不应是事后考虑,而应融入开发全流程 开源共享与商业机密保护可以找到平衡点 持续迭代与用户反馈是优化系统的关键 我们期待更多开发者加入这个开源项目,共同构建更强大的卡密生态系统。立即访问Gitee仓库(https://gitee.com/bandit-qing/auth)获取代码,或使用我们的免费加密平台(php.javait.cn)保护您的PHP应用。 未来路线图: 增加更多身份验证集成(如OAuth2.0) 开发可视化规则配置界面 支持区块链技术进行卡密存证 构建跨平台客户端SDK 完善开发者文档与教程体系 安全与用户体验的道路没有终点,我们将持续探索前沿技术,为开发者提供更优质的工具和服务。欢迎通过Gitee提交您的建议和贡献!
-
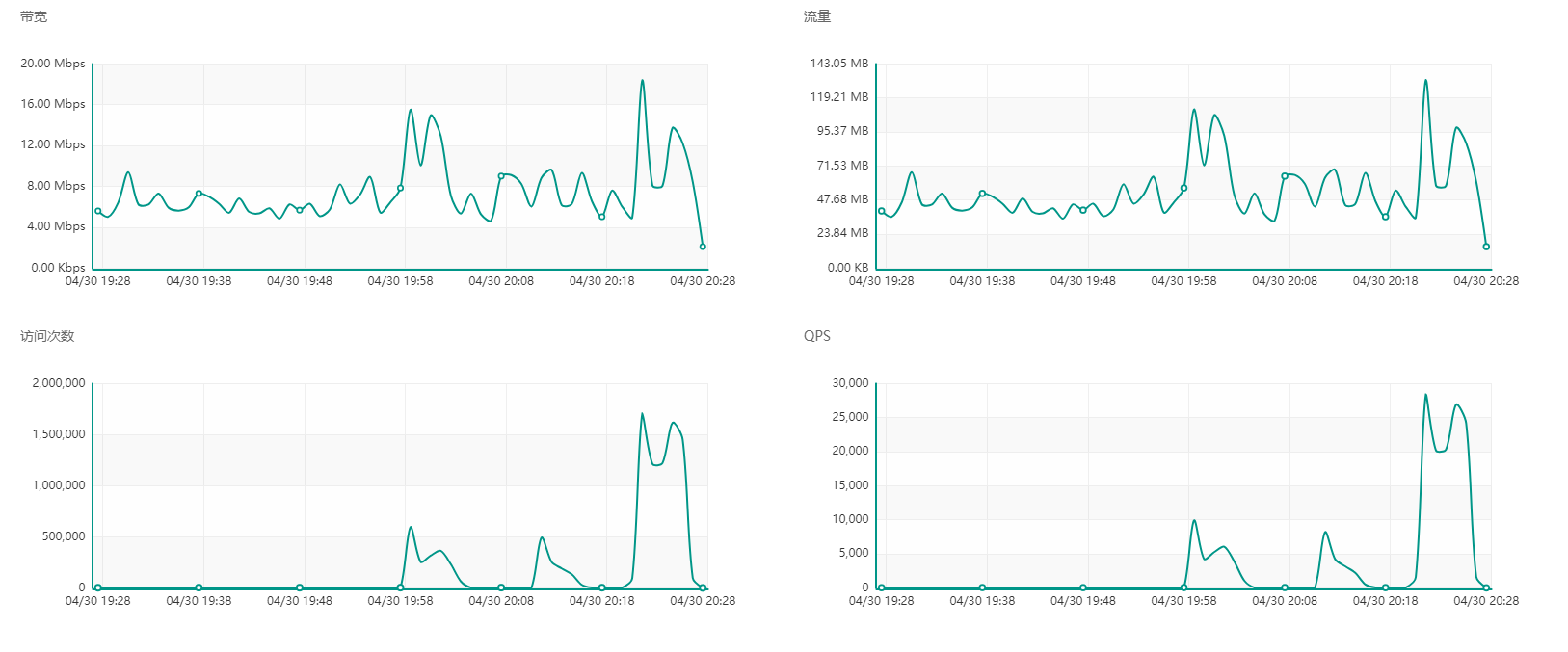
从CDN监控数据透视网站安全运维:实战防御与智能预警体系 从CDN监控数据透视网站安全运维:实战防御与智能预警体系 引言 随着网络攻击的不断演变和复杂化,网站的安全运维面临着前所未有的挑战。泛播科技CDN内容分发平台(cdn.fbidc.cn)通过实时监控和智能预警体系,为网站提供了多层次的安全防护。本文将通过分析CDN的实时监控数据,探讨如何通过实战防御和智能预警体系保障网站的安全运维。 23.png图片 24.png图片 一、CDN实时监控数据的重要性 CDN(内容分发网络)通过在全球范围内分布节点,将内容分发到离用户最近的服务器上,从而加速内容的访问速度。然而,CDN不仅仅是一个加速工具,更是网站安全防护的重要一环。实时监控数据可以帮助运维人员及时发现和处理潜在的安全威胁。 1.1 带宽监控 带宽是评估CDN性能的重要指标之一。通过实时监控带宽使用情况,可以发现异常流量,如DDoS攻击等。泛播科技CDN平台通过SYN Cookie防护,可以有效处理800Gbps以下的流量攻击。 1.2 流量监控 流量监控是评估CDN负载和性能的重要手段。通过监控流量数据,可以发现异常访问行为,如慢速攻击(Slowloris)等。泛播科技CDN平台通过HTTP异常检测,可以有效防御此类攻击。 1.3 访问次数监控 访问次数是评估网站受欢迎程度的重要指标。然而,异常高的访问次数可能是恶意刷量行为。通过实时监控访问次数,可以发现和处理此类异常行为。 1.4 QPS监控 QPS(每秒查询数)是评估网站性能的重要指标。高QPS可能导致服务器过载,从而影响网站的正常访问。通过实时监控QPS,可以及时发现和处理性能瓶颈。 二、实战防御体系 泛播科技CDN内容分发平台通过三层防御体系,全面保障网站的安全运维。 2.1 网络层防护 网络层防护主要通过SYN Cookie防护,可以有效处理800Gbps以下的流量攻击,确保CDN节点的正常运行。 2.2 协议层防护 协议层防护主要通过HTTP异常检测,可以有效防御如Slowloris等攻击,确保HTTP协议的稳定运行。 2.3 应用层防护 应用层防护通过AI行为分析,识别高级持续性威胁,确保应用层的安全。 三、成功案例 2025年,泛播科技CDN成功防御了持续5天的混合攻击,峰值达到742Gbps。这一成功案例展示了泛播科技CDN在应对复杂网络攻击方面的强大能力。 四、总结 泛播科技CDN内容分发平台通过实时监控和智能预警体系,为网站提供了多层次的安全防护。通过带宽、流量、访问次数、QPS等监控数据的分析,可以发现和处理各种潜在的安全威胁。未来,随着网络攻击的不断演变,泛播科技将继续致力于提升CDN的安全防护能力,为网站的安全运维保驾护航。
-
Go语言字母异位词分组算法详细解析 Go语言字母异位词分组算法详细解析 下面我将从算法思路、代码结构、执行流程、复杂度分析和优化方向五个方面,详细解析这段Go语言实现的字母异位词分组算法。 leetcode.jpg图片 1. 算法思路 核心思想 字母异位词的特点是字母组成相同但排列顺序不同。基于此特点,我们可以: 将每个字符串排序,排序后的字符串作为异位词的统一标识 使用哈希表(map)存储:排序后字符串 → 原始字符串列表的映射 最后收集哈希表中的所有值作为结果 为什么这样设计? 排序:将不同顺序但相同字母组成的字符串统一化 哈希表:提供O(1)时间复杂度的查找和插入操作 分组收集:直接提取哈希表的值就是所需结果 2. 代码结构解析 import ( "sort" "strings" ) func groupAnagrams(strs []string) [][]string { // 1. 初始化哈希表 groups := make(map[string][]string) // 2. 遍历所有字符串 for _, str := range strs { // 2.1 字符串排序 s := strings.Split(str, "") sort.Strings(s) sortedStr := strings.Join(s, "") // 2.2 分组存储 groups[sortedStr] = append(groups[sortedStr], str) } // 3. 结果收集 result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }关键部分解析 字符串排序处理: s := strings.Split(str, "") // 将字符串拆分为字符切片 sort.Strings(s) // 对字符切片排序 sortedStr := strings.Join(s, "") // 重新组合为字符串 strings.Split(str, ""):将字符串拆分为单个字符组成的切片 sort.Strings(s):对字符切片进行字典序排序 strings.Join(s, ""):将排序后的字符切片重新组合为字符串 哈希表分组: groups[sortedStr] = append(groups[sortedStr], str) 使用排序后的字符串作为key 将原始字符串追加到对应的分组中 结果收集: result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } 预分配足够容量的切片(性能优化) 遍历哈希表的值并收集到结果切片中 3. 执行流程示例 以输入 ["eat","tea","tan","ate","nat","bat"] 为例: 原始字符串排序后哈希表变化"eat""aet"{"aet": ["eat"]}"tea""aet"{"aet": ["eat", "tea"]}"tan""ant"{"aet": ["eat", "tea"], "ant": ["tan"]}"ate""aet"{"aet": ["eat", "tea", "ate"], "ant": ["tan"]}"nat""ant"{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"]}"bat""abt"{"aet": ["eat", "tea", "ate"], "ant": ["tan", "nat"], "abt": ["bat"]}最终结果:[["eat","tea","ate"],["tan","nat"],["bat"]] 4. 复杂度分析 时间复杂度 字符串排序:O(klogk),k是字符串长度 遍历所有字符串:O(n) 总时间复杂度:O(n*klogk) 空间复杂度 哈希表存储:O(n*k) 总空间复杂度:O(n*k) 其中: n:字符串数量 k:字符串的平均长度 5. 优化方向 1. 计数法优化(避免排序) func groupAnagrams(strs []string) [][]string { groups := make(map[[26]int][]string) for _, str := range strs { count := [26]int{} for _, c := range str { count[c-'a']++ } groups[count] = append(groups[count], str) } result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }优势: 时间复杂度降为O(n*k) 特别适合长字符串的情况 注意: Go中数组可以作为map key(切片不行) 需要处理Unicode时需扩展计数数组 2. 并行处理 对于超大字符串数组,可以: 将输入切片分成多个块 使用goroutine并行处理每个块 合并各个goroutine的结果 6. 关键点总结 排序是关键:通过排序将异位词统一化 哈希表高效分组:利用O(1)的查找和插入 Go语言特性: strings.Split/Join处理字符串 sort.Strings进行排序 map的灵活使用 性能考量: 预分配结果切片容量 考虑字符串长度选择排序法或计数法 这个实现充分展示了Go语言在处理字符串和哈希表方面的能力,代码清晰且效率较高。
-
字母异位词分组:Go/Java/Python最优解法详解 字母异位词分组:Go/Java/Python最优解法详解 问题描述 字母异位词(Anagram)是指由相同字母重新排列组合形成的不同单词。本题要求: 给定一个字符串数组 strs,将其中所有字母异位词组合在一起,可以按任意顺序返回结果列表。 leetcode.jpg图片 示例:输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"] 输出: [["bat"],["nat","tan"],["ate","eat","tea"]]解题思路 核心思路 字母异位词的特点是字母组成相同但顺序不同。我们可以利用这个特点: 将每个字符串排序,排序后的字符串作为异位词的统一标识 使用哈希表存储:排序后字符串 → 原始字符串列表的映射 最后将哈希表中的所有值收集起来就是结果 复杂度分析 时间复杂度:O(n*klogk),n是字符串数量,k是字符串最大长度(排序每个字符串的耗时) 空间复杂度:O(nk),需要存储所有字符串 各语言最优实现 Go实现 import ( "sort" "strings" ) func groupAnagrams(strs []string) [][]string { groups := make(map[string][]string) for _, str := range strs { // 将字符串转为字符数组并排序 s := strings.Split(str, "") sort.Strings(s) sortedStr := strings.Join(s, "") // 将原始字符串加入对应分组 groups[sortedStr] = append(groups[sortedStr], str) } // 收集结果 result := make([][]string, 0, len(groups)) for _, v := range groups { result = append(result, v) } return result }特点: 使用strings.Split和sort.Strings进行字符串排序 make(map[string][]string)创建哈希表 最后需要将map转为slice Java实现 import java.util.*; class Solution { public List<List<String>> groupAnagrams(String[] strs) { Map<String, List<String>> map = new HashMap<>(); for (String str : strs) { // 将字符串转为字符数组并排序 char[] chars = str.toCharArray(); Arrays.sort(chars); String sorted = new String(chars); // 如果不存在该key,则新建一个列表 if (!map.containsKey(sorted)) { map.put(sorted, new ArrayList<>()); } map.get(sorted).add(str); } return new ArrayList<>(map.values()); } }特点: 使用Arrays.sort()对字符数组排序 需要处理key不存在的情况 new ArrayList<>(map.values())直接转换结果 Python3实现 from collections import defaultdict def groupAnagrams(strs): groups = defaultdict(list) for s in strs: # 排序字符串作为key key = "".join(sorted(s)) groups[key].append(s) return list(groups.values())特点: 使用defaultdict简化代码 sorted(s)直接返回排序后的字符列表 代码最为简洁 边界情况测试 测试用例说明预期结果[""]空字符串[[""]]["a"]单个字符[["a"]]["eat","tea","tan","ate","nat","bat"]常规情况[["bat"],["nat","tan"],["ate","eat","tea"]]["abc","cba","bac","def","fed"]多个分组[["def","fed"],["abc","cba","bac"]]算法优化思路 计数法优化(避免排序) 我们可以统计每个字符串中各个字母的出现次数,用计数作为key: def groupAnagrams(strs): groups = defaultdict(list) for s in strs: count = [0] * 26 for c in s: count[ord(c) - ord('a')] += 1 groups[tuple(count)].append(s) return list(groups.values())复杂度分析: 时间复杂度:O(n*k),n是字符串数量,k是字符串最大长度 空间复杂度:O(nk) 这种方法在字符串较长时效率更高。 实际应用场景 单词游戏:如 Scrabble 等字母排列游戏 文本分析:查找相似单词 密码学:分析字母频率模式 数据清洗:识别和合并相似条目 总结 字母异位词分组问题的核心在于: 找到合适的分组标识(排序后的字符串或字母计数) 使用哈希表高效分组 处理各种边界情况 三种语言的实现展示了不同语言的特性: Go:显式类型转换较多,性能优秀 Java:类型系统严格,代码稍显冗长 Python:利用高级数据结构,代码最简洁 建议读者: 先理解排序法的思路 尝试实现计数法优化 比较不同语言的实现差异 扩展思考 如果字符串包含Unicode字符,如何修改算法? 如何优化内存使用,特别是处理大量长字符串时? 如何并行化处理这个分组问题? 希望这篇文章能帮助你彻底掌握字母异位词分组问题!如有任何疑问,欢迎在评论区讨论。
-
一篇文章彻底掌握「两数之和」:Go语言写法最优解法详解 问题描述 「两数之和」是LeetCode上最经典的算法题之一,题目要求: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 target 的那两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 leetcode.jpg图片 示例: 输入:nums = [2, 7, 11, 15], target = 9 输出:[0, 1](因为 nums[0] + nums[1] = 2 + 7 = 9) 2. 算法思路 暴力法(Brute Force) 最直观的方法是双重循环遍历所有可能的组合,时间复杂度 O(n²),但效率较低。 哈希表优化法(最优解) 利用 哈希表(Hash Map) 存储 值 → 索引 的映射,只需遍历一次数组: 遍历数组,计算 target - nums[i] 是否在哈希表中。 如果在,说明找到了解,直接返回两个索引。 如果不在,把当前 nums[i] 存入哈希表,继续遍历。 时间复杂度:O(n)(只需遍历一次) 空间复杂度:O(n)(需要存储哈希表) 3. 代码解析 修正后的代码 package main import "fmt" func twoSum(nums []int, target int) []int { m := make(map[int]int) // 哈希表:存储 值 → 索引 的映射 for i, v := range nums { if k, ok := m[target-v]; ok { // 检查 target - v 是否在哈希表中 return []int{k, i} // 如果存在,返回两个索引 } m[v] = i // 否则,存入当前值及其索引 } return nil // 没找到解,返回 nil } func main() { result := twoSum([]int{2, 7, 11, 15}, 9) fmt.Println(result) // 输出 [0, 1] }逐行解析 m := make(map[int]int) 创建哈希表 m,用于存储 值 → 索引 的映射。 for i, v := range nums 遍历数组 nums,i 是索引,v 是当前值。 if k, ok := m[target-v]; ok 检查 target - v 是否在哈希表中: 如果存在 ok = true,说明之前已经存储了一个数 nums[k],使得 nums[k] + v = target。 直接返回 [k, i]。 m[v] = i 如果没找到匹配,就把当前 v 和它的索引 i 存入哈希表,供后续查找。 return nil 如果遍历完数组仍然没找到解,返回 nil(Go 里表示空切片)。 main() 函数 调用 twoSum 并打印结果。 4. 执行流程(以 nums = [2, 7, 11, 15], target = 9 为例) 步骤ivtarget - v哈希表 m是否找到?操作1029 - 2 = 7{}否m[2] = 02179 - 7 = 2{2:0}是(m[2] = 0)返回 [0, 1]最终输出:[0, 1] 5. 复杂度分析 方法时间复杂度空间复杂度暴力法(双重循环)O(n²)O(1)哈希表优化法O(n)O(n) 时间复杂度 O(n):只需遍历一次数组,哈希表查找是 O(1)。 空间复杂度 O(n):最坏情况下需要存储所有元素。 6. 边界情况 无解情况 如果 nums = [1, 2, 3], target = 7,返回 nil。 重复元素 nums = [3, 3], target = 6 → 返回 [0, 1](哈希表不会覆盖,因为找到解时直接返回)。 负数 & 零 nums = [-1, 0, 1], target = 0 → 返回 [0, 2]。 空数组 nums = [], target = 1 → 返回 nil。 7. 总结 最优解法:哈希表(O(n) 时间,O(n) 空间)。 核心思路:用哈希表存储遍历过的值,避免重复计算。 Go 实现要点: map[int]int 存储 值 → 索引。 if k, ok := m[target-v]; ok 判断是否存在解。 main() 不能有返回值,应该打印结果。 这样,这段代码就能高效地解决 Two Sum 问题! 🚀