找到
56
篇与
Python教程
相关的结果
-
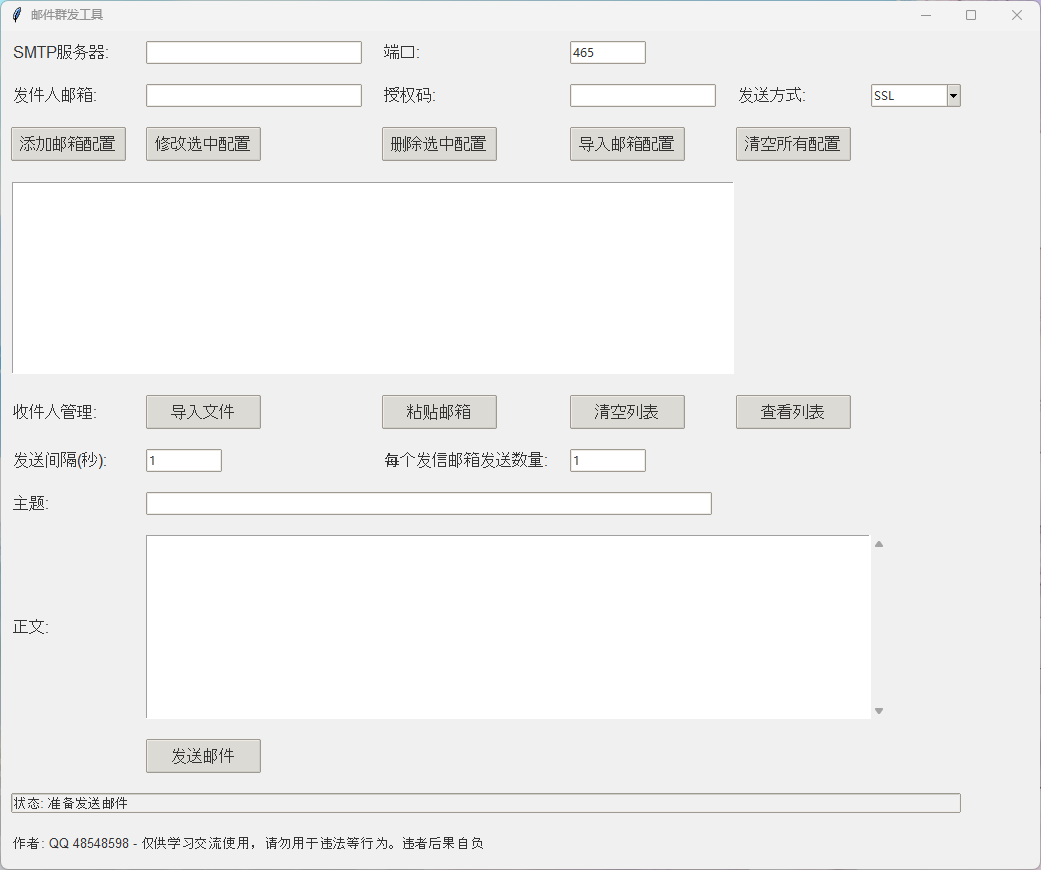
 企业营销邮件助手软件开源代码 邮件群发工具使用指南 1. 引言 在日常工作中,我们经常需要发送大量的邮件给不同的收件人。手动发送不仅耗时,而且容易出错。为此,开发了一款邮件群发工具,可以帮助用户高效地完成邮件群发任务。 2. 工具界面介绍 以下是邮件群发工具的界面截图: 邮件群发.png图片 3. 使用步骤 3.1 配置SMTP服务器 SMTP服务器: 输入你的SMTP服务器地址。 端口: 默认为465(SSL),可以根据实际情况调整。 发件人邮箱: 输入用于发送邮件的邮箱地址。 授权码: 输入邮箱的授权码或密码。 发送方式: 选择SSL或其他加密方式。 3.2 管理收件人 添加邮箱配置: 点击按钮可以添加新的邮箱配置。 修改选中配置: 修改当前选中的邮箱配置。 删除选中配置: 删除当前选中的邮箱配置。 导入邮箱配置: 导入已保存的邮箱配置文件。 清空所有配置: 清除所有已配置的邮箱信息。 3.3 收件人管理 导入文件: 导入包含收件人列表的文件。 粘贴邮箱: 直接粘贴收件人邮箱地址。 清空列表: 清空当前收件人列表。 查看列表: 查看当前收件人列表。 3.4 发送设置 发送间隔(秒): 设置每次发送邮件之间的间隔时间,默认为1秒。 每个发信邮箱发送数量: 设置每个发信邮箱最多发送的邮件数量,默认为1封。 3.5 编辑邮件内容 主题: 输入邮件的主题。 正文: 输入邮件的正文内容。 3.6 发送邮件 点击“发送邮件”按钮,开始发送邮件。 4. 注意事项 合法合规: 请确保邮件内容合法合规,不要用于非法用途。 隐私保护: 尊重收件人的隐私,不要滥用此工具。 网络环境: 确保网络环境稳定,避免因网络问题导致邮件发送失败。 5. 结语 通过这款邮件群发工具,你可以轻松地完成大量邮件的发送任务,提高工作效率。希望本文对你有所帮助! 希望这篇博客文章能帮助你更好地理解和使用邮件群发工具! 图片说明 SMTP服务器: 输入SMTP服务器地址。 端口: 默认为465(SSL)。 发件人邮箱: 输入发件人邮箱地址。 授权码: 输入授权码。 发送方式: 选择SSL或其他加密方式。 收件人管理: 包括导入文件、粘贴邮箱、清空列表和查看列表。 发送间隔: 设置发送间隔时间。 每个发信邮箱发送数量: 设置每个发信邮箱发送的数量。 主题: 输入邮件主题。 正文: 输入邮件正文内容。 发送邮件: 点击按钮发送邮件。 邮件群发工具软件代码: 隐藏内容,请前往内页查看详情 仅供学习交流使用,请勿用于违法等行为。违者后果自负
企业营销邮件助手软件开源代码 邮件群发工具使用指南 1. 引言 在日常工作中,我们经常需要发送大量的邮件给不同的收件人。手动发送不仅耗时,而且容易出错。为此,开发了一款邮件群发工具,可以帮助用户高效地完成邮件群发任务。 2. 工具界面介绍 以下是邮件群发工具的界面截图: 邮件群发.png图片 3. 使用步骤 3.1 配置SMTP服务器 SMTP服务器: 输入你的SMTP服务器地址。 端口: 默认为465(SSL),可以根据实际情况调整。 发件人邮箱: 输入用于发送邮件的邮箱地址。 授权码: 输入邮箱的授权码或密码。 发送方式: 选择SSL或其他加密方式。 3.2 管理收件人 添加邮箱配置: 点击按钮可以添加新的邮箱配置。 修改选中配置: 修改当前选中的邮箱配置。 删除选中配置: 删除当前选中的邮箱配置。 导入邮箱配置: 导入已保存的邮箱配置文件。 清空所有配置: 清除所有已配置的邮箱信息。 3.3 收件人管理 导入文件: 导入包含收件人列表的文件。 粘贴邮箱: 直接粘贴收件人邮箱地址。 清空列表: 清空当前收件人列表。 查看列表: 查看当前收件人列表。 3.4 发送设置 发送间隔(秒): 设置每次发送邮件之间的间隔时间,默认为1秒。 每个发信邮箱发送数量: 设置每个发信邮箱最多发送的邮件数量,默认为1封。 3.5 编辑邮件内容 主题: 输入邮件的主题。 正文: 输入邮件的正文内容。 3.6 发送邮件 点击“发送邮件”按钮,开始发送邮件。 4. 注意事项 合法合规: 请确保邮件内容合法合规,不要用于非法用途。 隐私保护: 尊重收件人的隐私,不要滥用此工具。 网络环境: 确保网络环境稳定,避免因网络问题导致邮件发送失败。 5. 结语 通过这款邮件群发工具,你可以轻松地完成大量邮件的发送任务,提高工作效率。希望本文对你有所帮助! 希望这篇博客文章能帮助你更好地理解和使用邮件群发工具! 图片说明 SMTP服务器: 输入SMTP服务器地址。 端口: 默认为465(SSL)。 发件人邮箱: 输入发件人邮箱地址。 授权码: 输入授权码。 发送方式: 选择SSL或其他加密方式。 收件人管理: 包括导入文件、粘贴邮箱、清空列表和查看列表。 发送间隔: 设置发送间隔时间。 每个发信邮箱发送数量: 设置每个发信邮箱发送的数量。 主题: 输入邮件主题。 正文: 输入邮件正文内容。 发送邮件: 点击按钮发送邮件。 邮件群发工具软件代码: 隐藏内容,请前往内页查看详情 仅供学习交流使用,请勿用于违法等行为。违者后果自负
-
Python小练习题目二 题目内容: 第一题 : 键盘输入一个4位数,判断是否为回文数。 所谓回文数,就是各位数字从高位到低位正序排列和从低位到高位逆序排列都是同一数值的数,例如,数字1221按正序和逆序排列都为1221,因此1221就是一个回文数;而1234的各位按倒序排列是4321,4321与1234不是同一个数,因此1234就不是一个回文数。 示例1: 输入: 请输入一个四位数:1221 输出: 1221 是回文数 示例2: 输入: 请输入一个四位数:1200 输出: 1200 不是回文数 答案: def is_palindrome(n): # 将数字转换为字符串,方便操作 str_n = str(n) # 检查数字是否恰好是四位数 if len(str_n) == 4: # 使用切片操作来反转字符串 reversed_n = str_n[::-1] # 比较原字符串和反转后的字符串是否相同 return str_n == reversed_n else: # 如果不是四位数,返回False return False # 从用户那里获取输入 num_input = input("请输入一个四位数:") # 尝试将输入转换为整数,并检查是否为四位数 try: num = int(num_input) if 1000 <= num <= 9999: # 判断是否为回文数 if is_palindrome(num): print(f"{num} 是回文数") else: print(f"{num} 不是回文数") else: print("输入的不是一个四位数,请重新输入。") except ValueError: print("输入的不是一个有效的数字,请重新输入。") 第二题: 请用程序实现下表所示某商场积分与会员的对应规则: 会员积分规则 会员积分 会员级别 0 注册会员 0< score≤2000 铜牌会员 2000 < score≤10000 银牌会员 10000 < score≤30000 金牌会员 score >30000 钻石会员 说明:请使用if..elif...else语句 示例: 输入:请输入您的会员积分:2500 输出:银牌会员 答案: def pythonit(sore): if sore == 0: print("会员等级为:注册会员") elif 0 < sore <= 2000: print("会员等级为:铜牌会员") elif 2000 < sore <= 10000: print("会员等级为:银牌会员") elif 10000 < sore <= 30000: print("会员等级为:金牌会员") elif sore > 30000: print("会员等级为:钻石会员") else: print("你并不是会员用户") sore = int(input("请输入您的积分:")) pythonit(sore) 第三题: 哥哥带着弟弟去游乐场玩,游乐场规定未满12岁的儿童须由年满18周岁的成年人陪同才能进入,请编写代码判断弟弟能否进入游乐场。 示例1: 输入: 哥哥的年龄是:16 弟弟的年龄是:10 输出: 不能进入 示例2: 输入: 哥哥的年龄是:18 弟弟的年龄是:10 输出: 可以进入 答案: def can_enter_amusement_park(elder_brother_age, younger_brother_age): # 判断哥哥是否年满18周岁 if elder_brother_age >= 18: # 判断弟弟是否未满12周岁 if younger_brother_age < 12: return "可以进入" else: return "不能进入(弟弟已满12周岁)" else: return "不能进入(哥哥未满18周岁)" # 示例1 elder_brother_age_1 = int(input("哥哥的年龄是:")) younger_brother_age_1 = int(input("弟弟的年龄是:")) print(can_enter_amusement_park(elder_brother_age_1, younger_brother_age_1)) # 示例2 elder_brother_age_2 = 18 younger_brother_age_2 = 10 print(can_enter_amusement_park(elder_brother_age_2, younger_brother_age_2))
-
Python小练习题目一 1.打印某学校的校训,具体内容如下所示: 勤奋 严谨 求实 创新 注意: 第一行和最后一行各有 30 个*号。 答案: school_strs = "勤奋 严谨 求实 创新" print("*" * 30) print(school_strs) print("*" * 30)2.请用程序实现:输入摄氏温度,计算并输出相对应的华氏温度,华氏温度=摄氏温度×1.8+32。注意:输出时华氏温度保留两位小数。 示例1 :输入 36.5 输出 97.70 答案: wendu_nums = float(input("请输入摄氏温度: ")) result = wendu_nums * 1.8 + 32 print(f"对应的华氏温度为: {result:.2f}")3.请用程序实现:输入直角三角形两个直角边的长度 a, b,计算并输出直角三角形的斜边长c。 注:直角三角形三边满足,a² + b² = c²;斜边长度保留两位小数; 示例1: 输入(使用空格分隔多数据输入) 3.0 4.0 输出 5.00 示例2:输入(使用空格分隔多数据输入) 18.0 30.0 输出 34.99 答案: import math a, b = map(float, input("请输入两个直角边的长度(用空格分隔):").split()) c = math.sqrt(a**2 + b**2) print(f"直角三角形的斜边长为: {c:.2f}")
-
Python爬虫Post请求教程 下面这段代码是一个简单的Python脚本,用于从Python之禅(一个Python中文技术博客)网站进行搜索查询,并输出搜索结果。以下是对这段代码的详细解释: 导入所需的库: urlopen 和 Request 是从 urllib.request 模块导入的,用于发送HTTP请求。 UserAgent 是从 fake_useragent 库导入的,用于生成随机的用户代理字符串,以模拟不同的浏览器。 quote 是从 urllib.parse 模块导入的,用于对URL中的特殊字符进行编码。 设置用户代理: 使用 UserAgent() 创建一个用户代理对象。 ua.chrome 获取一个模拟Chrome浏览器的用户代理字符串。 设置请求头: 创建一个字典 headers,其中包含一个 'User-Agent' 键,其值设置为模拟的Chrome浏览器的用户代理字符串。 获取用户输入: 使用 input 函数提示用户输入搜索内容,并将其存储在变量 key 中。 对搜索内容进行URL编码: 使用 quote 函数对 key 进行编码,以确保它可以安全地作为URL的一部分。 将编码后的搜索内容存储在 f_data 中。 构建URL: 创建一个URL字符串,该字符串包含搜索的基础URL和编码后的搜索内容。 创建请求对象: 使用 Request 创建一个请求对象,该对象包含URL、请求头和编码后的搜索内容(作为POST数据)。 发送请求并获取响应: 使用 urlopen 函数发送请求,并将响应对象存储在 reopen 中。 读取并打印响应内容: 使用 read 方法读取响应的内容。 使用 decode 方法将内容从字节串解码为字符串。 打印解码后的内容。 注意:虽然代码中使用了 data=f_data.encode() 来发送POST请求,但通常搜索查询是通过GET请求发送的,其中查询参数附加到URL中。因此,这里可能是一个错误或特定于该网站的特定实现。如果这是标准的GET请求,那么你应该将查询参数添加到URL中,而不是使用 data 参数。 此外,这段代码没有处理任何可能的异常,例如网络错误或无效的URL。在实际应用中,你可能需要添加异常处理来确保代码的健壮性。 from urllib.request import urlopen,Request from fake_useragent import UserAgent from urllib.parse import quote ua = UserAgent() headers = { 'User-Agent':ua.chrome } key = input('请输入搜索的内容:') f_data = quote(key) url = f'https://blog.javait.cn/index.php/search/{quote(key)}' req = Request(url,headers=headers,data=f_data.encode()) reopen = urlopen(req) print(reopen.read().decode())
-
Python爬虫Get请求教程 注意下面这些代码: 这个脚本直接打印出网页的HTML内容,而不是解析后的内容。如果你想要解析网页内容(如提取某些特定信息),你可能需要使用如BeautifulSoup之类的库。 这个脚本没有进行错误处理,例如网络错误或请求超时等。在实际应用中,你可能需要添加适当的错误处理机制。 使用 fake_useragent 生成随机用户代理有助于避免某些网站的防爬虫机制,但这并不能保证一定能成功绕过所有的防爬虫机制。某些网站可能会采用更复杂的策略来检测和阻止爬虫。 from urllib.request import urlopen,Request from fake_useragent import UserAgent from urllib.parse import quote search = input("请输入搜索的内容:") url = f"https://blog.javait.cn/index.php/search/{quote(search)}" ua = UserAgent() headers = { 'User-Agent': ua.chrome } re = Request(url,headers=headers) reopen = urlopen(re) print(reopen.read().decode())